A spin-off of the storytelling-for-marketing: we're bringing
storytelling into corporate teambuilding. We asked dozens of people and noticed that locally
"teambuilding" is only
paintball and field games, so the idea is to differentiate by having employees build a story
together. Each small team embodies a character drawn from a narrative
archetype, so they get to step into different personalities.
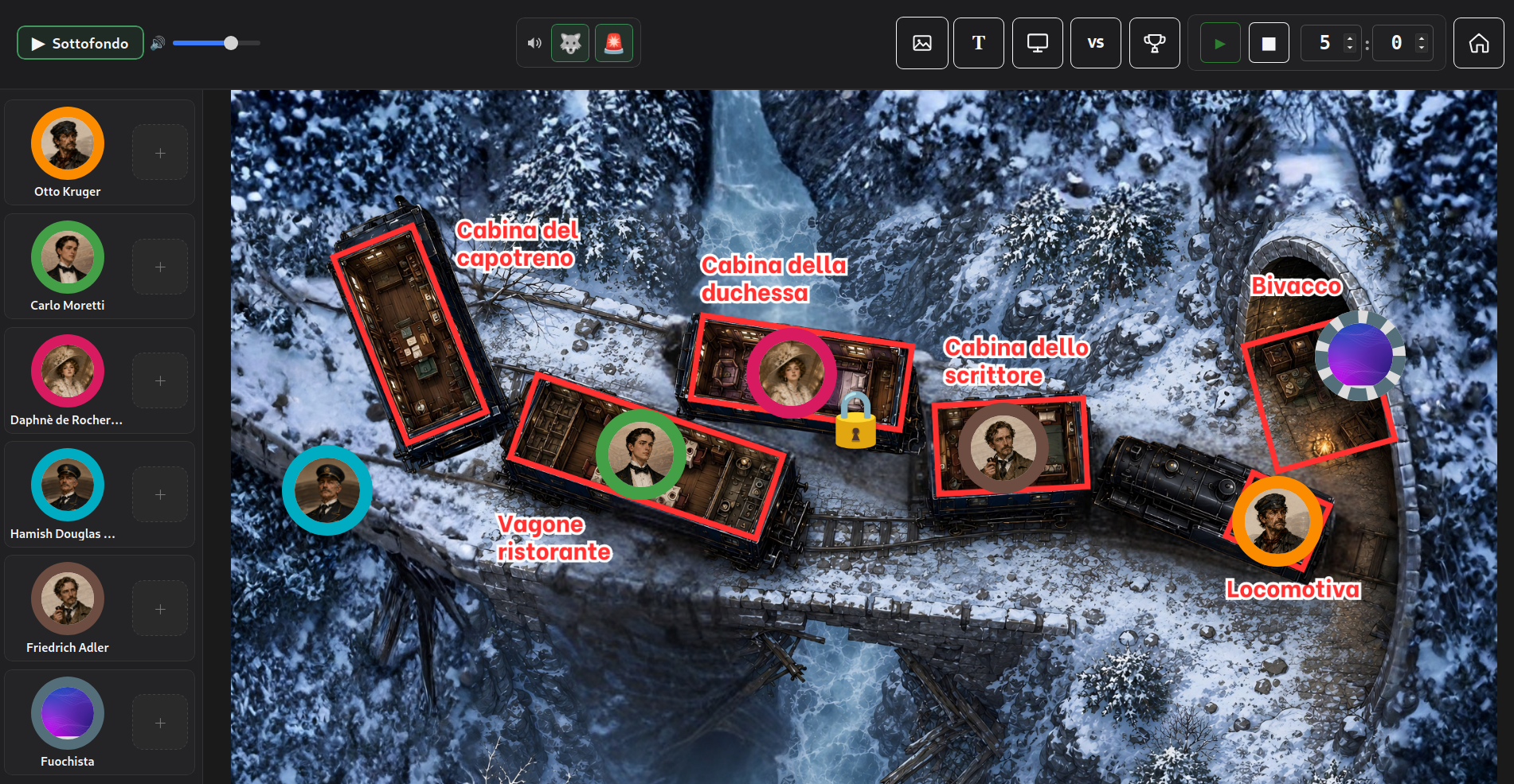
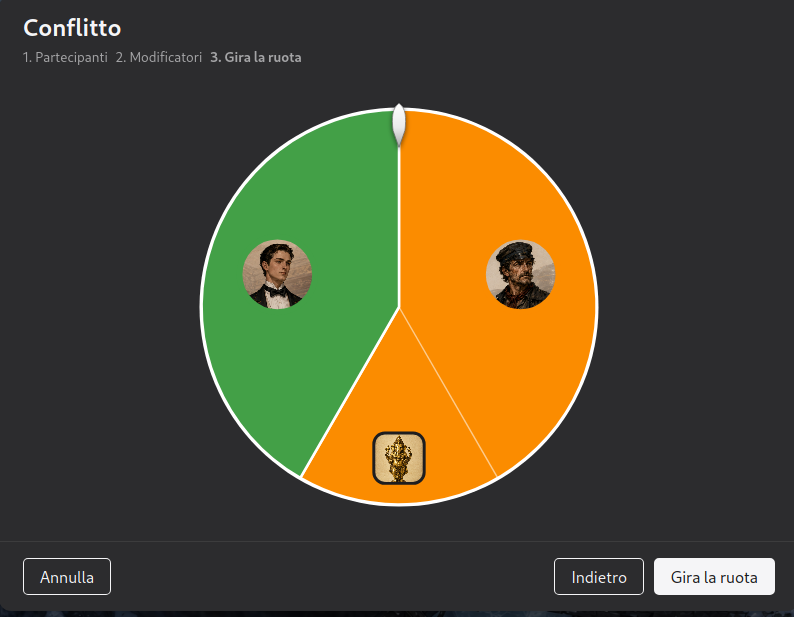
To run these sessions live I built a desktop tool that turns the event into a simplified tabletop RPG and
keeps everything easy and fun to manage. It runs on two windows: a control window with every knob (character
movement, conflicts, timer...) and a projection window.
Scenarios are self-contained folders (map, characters, objects...), so you can build
different scenarios. Since the goal is to
scale this activity, I deliberately picked a cross-platform stack (Tauri v2 + React 19 + TypeScript,
with a Rust backend for low-latency audio), and gave it a
self-explanatory, error-tolerant Italian UI (already in use by another non-technical person who had
no trouble with it).
With a writing coach friend, we've worked out a way to apply storytelling to marketing, first inside his own
business and then for a few acquaintances' businesses. Encouraged by the results, we decided to turn it into
a service, and we started pitching ourselves as speakers at workshops run by innovation hubs to make
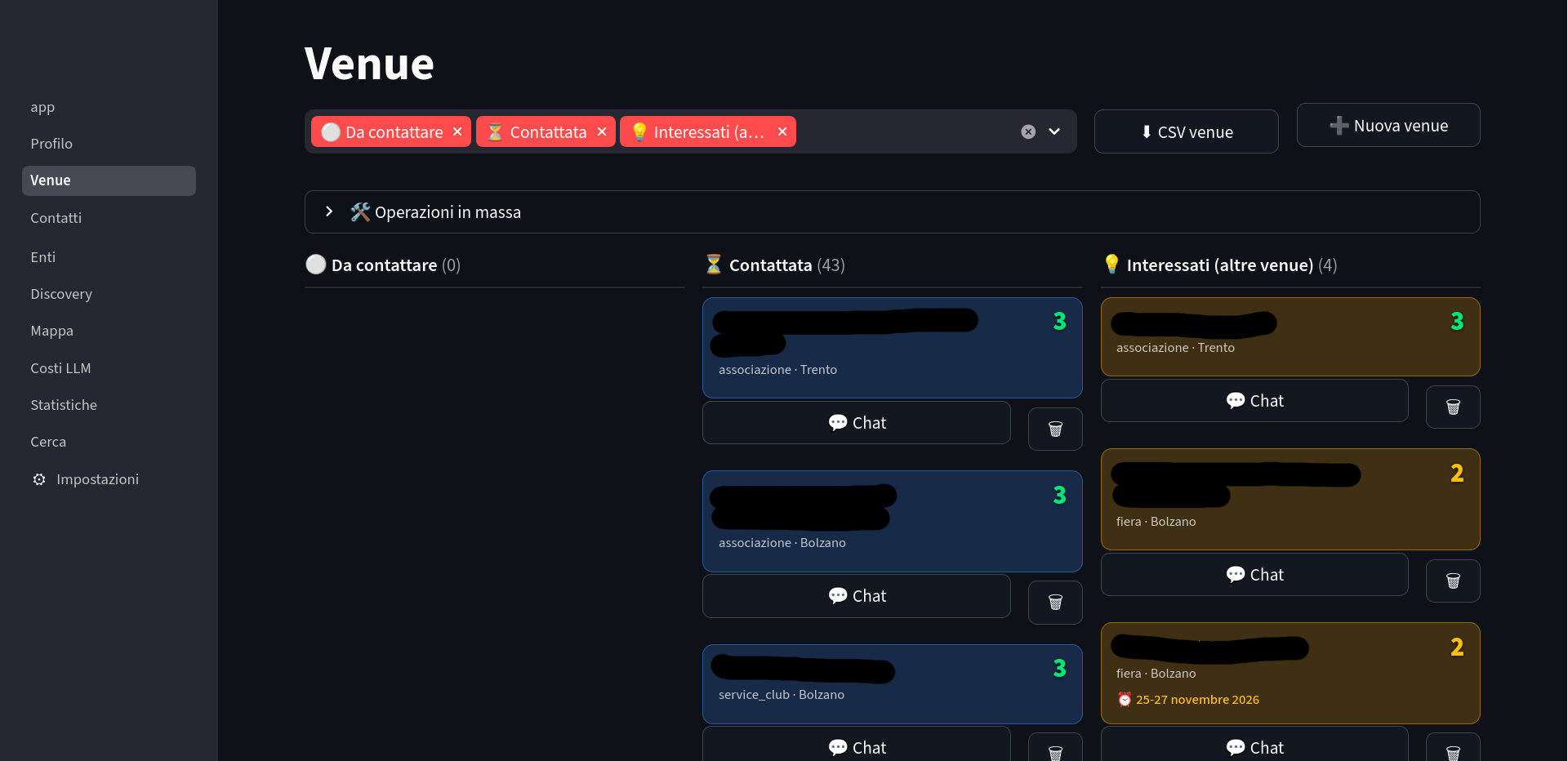
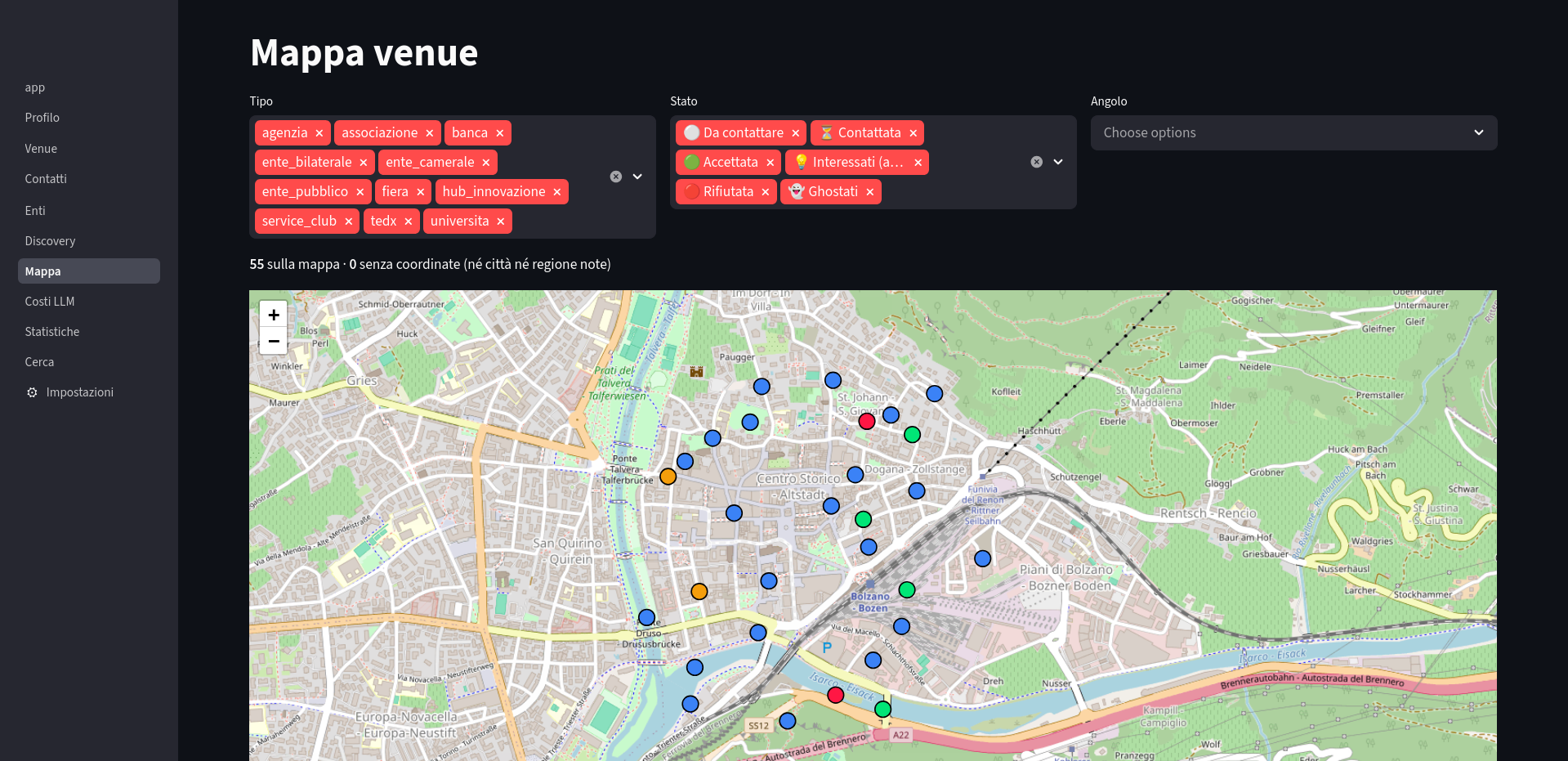
ourselves known. Response so far has been encouraging, so I built a desktop tool to scale the most boring
part: finding compatible venues, locating the right mail address, and producing a first draft.
The app (Python + Streamlit + SQLite, single file DB) keeps every venue, contact, and interaction. Before
drafting, it assembles a dossier for the LLM: the project profile, our bios, the history with that venue,
and an email-guidelines file (~600 lines of anti-AI-slop rules).
Nothing is sent automatically: the friction is deliberate, both to avoid spam and to catch the small
mistakes that slip into a draft. The tool tracks every send and reply, suggests when a follow-up is due, and
proposes what to write based on the conversation so far.
Following many (business, politics, communication...) YouTube channels, several podcasts, and Hacker News
requires too many hours a day. As much as I love spending hours on HN, it wasn't sustainable, so I built
three services that run on my home server and filter and summarize the content for
me.
YT Highlights pulls the latest videos from my subscribed channels, fetches the transcript (yt-dlp), and asks Claude to extract the key
points.
Podcast Highlights does the same for podcasts, both YouTube-hosted (with available transcript) and
native RSS (MP3 is downloaded and transcribed locally with faster-whisper). Surprisingly
lightweight as a service, and it spares me the usual share of conversation that doesn't add value.
HN Daily Digest fetches the top 200 Hacker News articles, ranks them against my declared interests
and picks the 30 most relevant, then pulls the comments and generates a summary of both the article and the
discussion. By letting Claude help me define my interests through questions and letting it write the prompt,
the filtered posts are remarkably precise: I ran a manual test on 200 articles and it worked perfectly!
The highlights become 3 RSS feeds that I read on Newsblur (not self-hosted).
Existing gym apps never fit what I need, so I built my own with Claude Code, following the same
file over app philosophy as my other
tools.
The core feature is a gitgraph dashboard: a 4×7 grid that shows whether I trained on each day and whether
tonnage improved over the previous session. On top of that, a few things I never found elsewhere: custom
exercises with execution notes, inline images (rendered from a link) to remind me of the correct form, and a
stretch timer that vibrates on every set so I don't have to stare at the screen while stretching.
I also integrated the Polar
H10 chest strap (one of the few that exposes more than just BPM) to track the cardiac side: live
ECG, pre-workout HRV
readiness (on a 14-day rolling baseline), a VO2max estimate (Uth-Sørensen-Overgaard formula, with Tanaka formula for HRmax), a
calorie estimate (Keytel equation), and training load via Banister
TRIMPexp.
The raw ECG is analyzed post-workout with Pan-Tompkins QRS detection plus screening for PACs, pauses,
irregular beats, and AFib
episodes. A 4-week self-diagnosis card summarizes 7 cardiac metrics (resting HR, HRR, VO2max, RMSSD, SDNN, cardiac drift, SD2/SD1) with conditional alerts when something is trending in the wrong direction.
It's obviously not clinical-grade, but still diagnostically useful as a long-term self-monitoring tool: I
finally gave some meaning to my master's degree.
I wanted to stop depending on cloud services for my personal data: photos, documents, music, books,
finances. Instead of buying dedicated hardware, I repurposed an old Lenovo laptop (i7-8550U, 12GB RAM, 1TB
NVMe + 2TB HDD) as a Debian server.
The server runs ~20 Docker services covering media (Immich, Navidrome, Kavita), productivity (Paperless-ngx, Paisa, DietPlanner), and media tracking (Yamtrack).
Some services I built myself to fill gaps (locally-built images triggered by cron): Paisa Input is a
mobile-first Flask micro-app that lets me log expenses from my phone into Paisa's ledger file; YT Highlights
is a Python script that pulls YouTube RSS feeds, extracts transcripts, sends them to Claude for highlights,
and publishes the result as an RSS feed.
The server has no public IP (ISP behind CGNAT), all access goes through Tailscale. This is the foundation of an 8-layer security architecture: Tailscale
with tag-based ACLs, UFW
firewall, AdGuard Home for
DNS-level ad/tracker blocking across all devices, Mullvad
DoH, Fail2ban on SSH, kernel-level audit
logging via auditd, gocryptfs encryption for
sensitive documents, and a real-time container whitelist that alerts me if an unauthorized Docker container
starts.
Every script and service reports to ntfy. About 15 monitoring
scripts cover everything from disk space and CPU temperature to kernel errors and SSH logins, all running on
cron or as systemd services. Uptime
Kuma checks every service endpoint every 60 seconds, Scrutiny tracks disk SMART attributes with historical trends, and Netdata handles real-time system metrics with
auto-discovery of Postgres and Redis instances. I also can shut down or reboot the server with a tap from my
phone through a custom ntfy listener.
Backups follow the 3-2-1 rule: Borg (encrypted,
deduplicated, compressed) to a local HDD repo, then rclone
to Backblaze B2 offsite. The nightly
job dumps the Immich Postgres database, archives everything, prunes old snapshots, and syncs to B2. A weekly
integrity check verifies the Borg repository.
The first DietPlanner didn't work exactly as I wanted, and Electron made
everything slow and clunky to work with... Having learned Claude Code, I used it to rebuild everything from
scratch as a local web app.
All the app on the market are built for real time tracking, and this doesn't fit well with how I think
about food: I need to design a diet (up to micronutrients), periodically refine it (quickly), and
then follow it.
DietPlanner 2.0 lets me build a personal ingredient database (importable from nutritionvalue.org), compose recipes with
nutritional charts, and assemble daily meal plans.
It also includes a caloric needs calculator (Harris-Benedict + TDEE, with macro targets and calorie presets)
and exports HTML grocery lists.
It follows a "File over app" approach: all
data lives as plain Markdown files.
My mother isn't very tech-savvy, and lately she's been scrolling through YouTube shorts to find recipes to
cook.
I took this opportunity to learn how to use Claude Code by creating an app that suggests recipes to my mom
based on her preferences.
In the settings, the user enters their preferences as a string, which are then passed on to the LLM during
recipe generation. The app offers three ways to generate recipes: periodically (time and days of the week
can be set), with a button on the home screen, or in a chat starting from the ingredients the user has.
The application has a very simple UI, suitable for an older person, and has a few essential features: you
can save recipes or chat with them to change ingredients
NOTE: to prevent the LLM from generating the same recipes, I used what was found in the paper on verbalized
sampling: I explicitly asked for low-probability responses, which greatly improved the variety of
recipes. I
also use this technique in LLM chats, asking to always append a short final paragraph with a response with a
probability <5%.
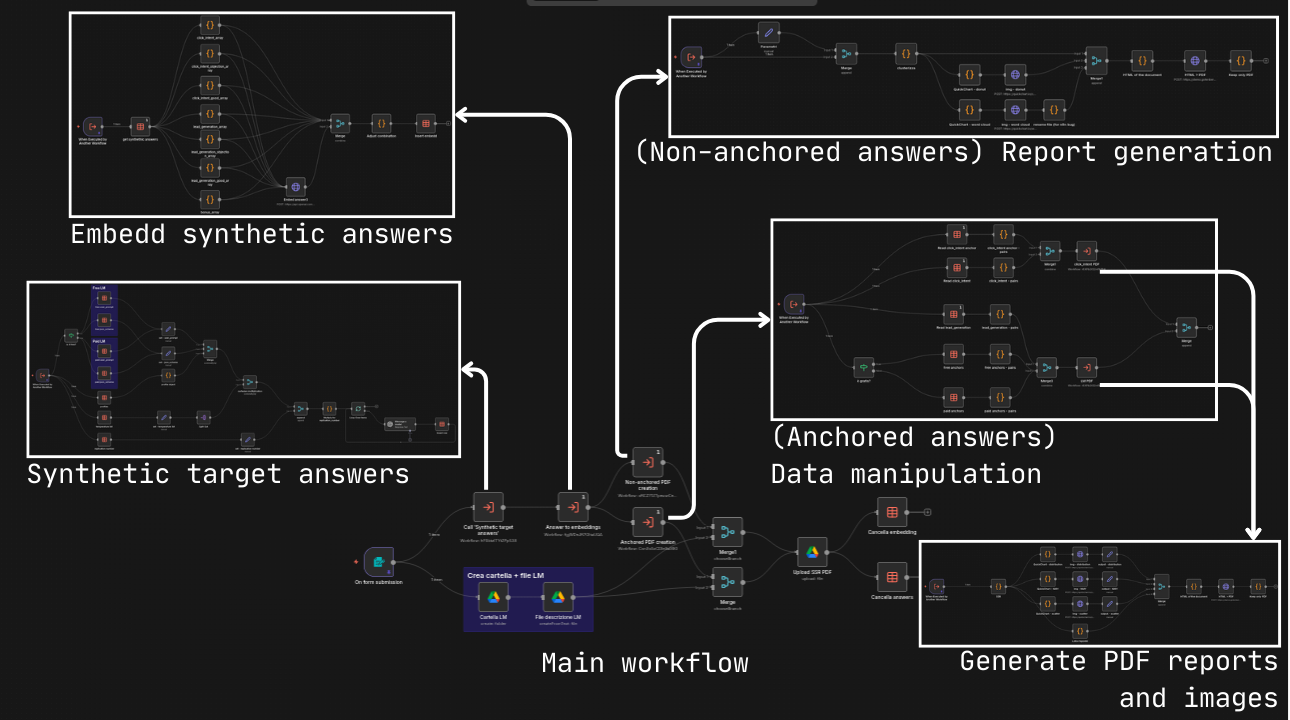
Replicating what was done in the paper “LLMs Reproduce Human Purchase Intent via Semantic Similarity
Elicitation of Likert Ratings,” I created a synthetic target audience based on descriptions of
current
customers of the business I worked with.
We used the synthetic audience to make decisions about products and advertising based on click and purchase
intent (using the Likert Ratings approach from the paper) but also on open questions by clustering the
results of the embeddings.
It was useful for providing direction, but since it is a very niche product (and therefore the (synthetic)
audience is very specific), the results tend to be binary: if the product meets the needs of the target
(which we know), there is high intent, otherwise it is very low.
I expect this tool to become much more useful in a context with less niche and more mass market products, as
was essentially found in the paper (which compared the results with surveys of personal care products).
A wiser use of this tool could be to generate a large audience as combinations of parameters (age,
preferences, economic availability, etc.) and understand, based on the results, which parameters most
influence
intention and thus define an ICP.
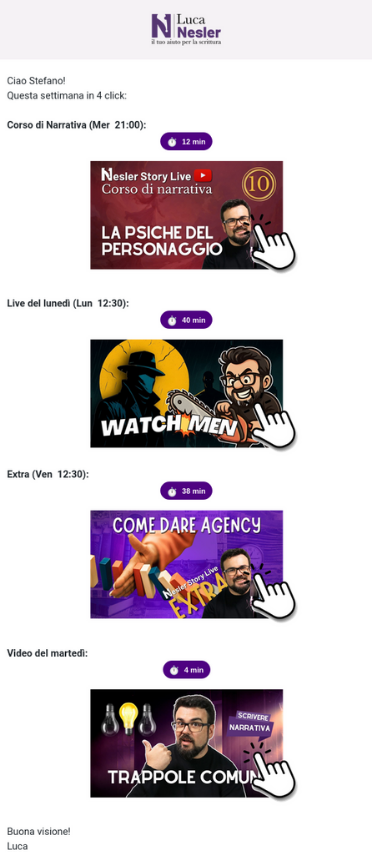
Reworked the client’s newsletter strategy by replacing 3 weekly “Have you seen this?” emails with a single
automatic weekly recap, which over 4 weeks increased the average open rate by +3.7% and the average click
rate by +1.1% on a list of ~2,000 subscribers.
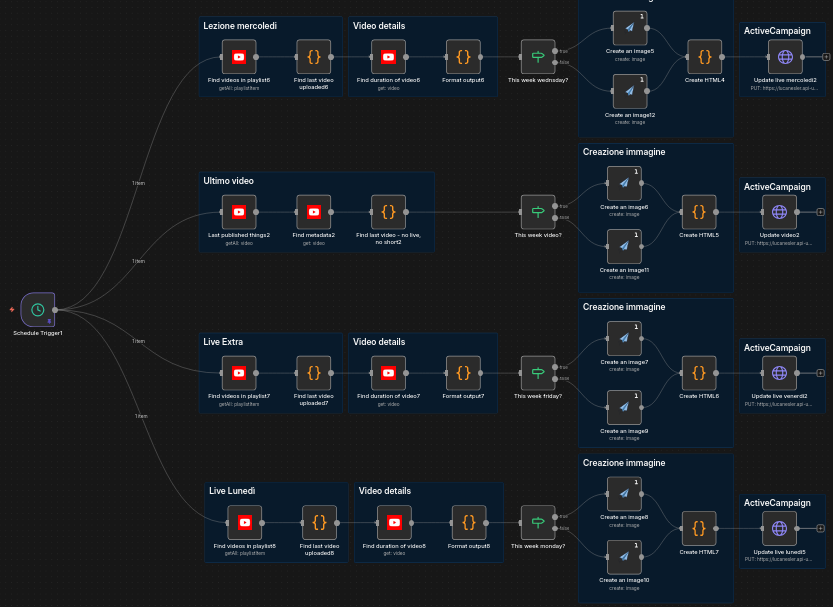
The recap is assembled by an n8n workflow: it pulls the
channel’s latest uploads, and writes them into an ActiveCampaign template that exposes HTML variables updated via HTTP calls, with
each video shown as a clickable thumbnail.
An n8n workflow that turns YouTube Live into a batch of Shorts.
In the first four weeks, generated ~32.000 views with ~8.800 engaged views and an average watch percentage
of ~60%, outperforming the client’s previous Shorts.
NOTE: the channel has ~5.000 subscribers with average video views ~300.
For every live, the automation ingests the recording, downloads the transcript, identifies multiple strong
moments, and produces ~10 Shorts.
Using Rendi, it cuts each segment, adds background
music, subtitles, and an outro with a CTA.
The Shorts are then uploaded to the channel as private so they can be reviewed before publishing.
NOTE: SaaS tools at $30/month failed to deliver the clip quality the client wanted, while this custom
workflow costs $4/month in LLM usage and is tailored to their needs.
Replaced a 1.000€/year course platform with a setup based on Google Drive and the client’s newsletter.
With the client, we defined a new funnel strategy: remove the old platform as an ineffective step and
deliver courses live on YouTube, with course materials stored in Drive and access gated by newsletter
signup. This change increased average live views from ~170 to ~400, boosted newsletter subscriptions,
encouraged users to move off the old platform, and made the newsletter a stronger entry point in the funnel.
To do that, a small Google Apps Script grants view access to the Drive folder as soon as someone subscribes:
ActiveCampaign sends a webhook with the email,
the script receives it and adds the user as a viewer, so access is automatic and needs no maintenance.
Helped a Swiss client clear a three month bookkeeping backlog in one month and stay current by automating
how bank, PayPal, and credit card data flows into their accounting spreadsheet.
The client initially asked for help “catching up” and we evaluated moving to a full accounting tool with
automatic bank connections, but given the complexity of Swiss bank integrations and the overhead of changing
systems, we agreed on a simpler automation that kept their spreadsheet and removed the repetitive work
instead of introducing a heavy new platform.
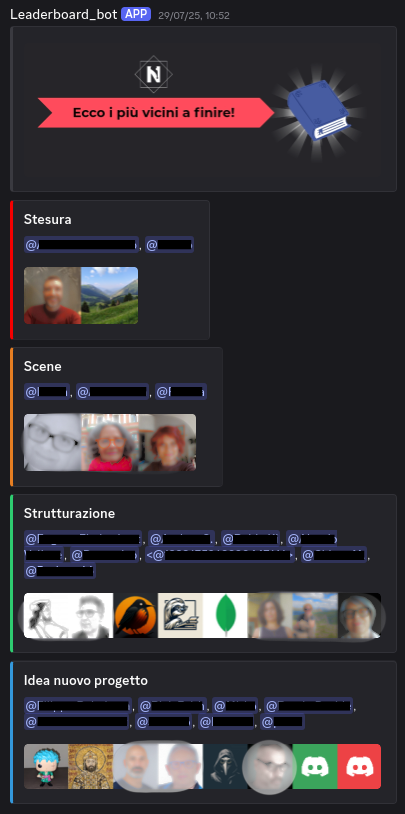
Increased engagement in client’s product Discord server by introducing a weekly, visual leaderboard that
created a recurring ritual within the community.
The lightweight Discord bot scans the server once a week, groups members by role, and generates a collage of
avatars.
It runs on fly.io as a tiny pay as you go container with built
in scheduling (to avoid complications should future changes be necessary) and is basically free to run at
this scale.
A simple dark theme for Obsidian, inspired by the design of this website. I focused on a clean layout with an emphasis on good contrast colors for better readability.
DietPlanner is a tool for proactive meal planning, designed to help users working toward body recomposition or similar nutrition goals. As often happens, I started this project to solve a personal problem: I wanted to plan my meals in advance, but most existing apps are built for real-time tracking. I also wanted something file over app like Obsidian, so I took this occasion to learn Electron.
After reading a lot of posts on HN, I realized it’s common to have a personal website to share projects, ideas, and updates about work and life. So, after years, I went back to HTML, CSS, and JS (feel free to laugh when you check the repo...). I considered using something more modern like React, but I wanted to keep things simple and not get lost in new tech.
My story was selected as one of the eight winners of the global UN competition "Sci-fAI Challenge". The competition involved writing a short story that explored the implications of AI on peace, security and warfare. As a winner, I was invited at the "Responsible AI in the Military domain Summit" (REAIM) to share my ideas on how artificial intelligence can shape peace-building and global security.
During this academic period, I focused on assignments. These included the simulation of cardiovascular pathologies, modeling the impact of treatments, and the analysis of the computational complexity of DNA sequencing algorithms. (You can find a detailed report for each project at the link.)
Most "should you study math?" content sells the romance of the subject. I wanted to do the opposite:
hand high schoolers the actual first-semester material and let them decide based on whether
they enjoy it and can keep up.
I wrote this ~50-page book during my first university year, with the concept of a set as the connecting
thread and topics requiring zero prior knowledge. It walks through formal notation, set operations and
proofs, the set-theoretic construction of numbers, and ends by deriving the divisibility criterias.
The thesis is in the title: if you don't enjoy these pages or find them too hard, a math degree probably
isn't for you.
I tried to get the Province of Bolzano's university orientation office to distribute it to students and was
told they "don't do that kind of thing"; I later found out the Province allocates far more money to
orienting middle and high schoolers, purely because that's compulsory schooling.
Final-year high school exam project developed with my friend: a fully functional RFID-based bike sharing system. It features a multilingual web platform (HTML, PHP, JS), a MySQL database, and a physical simulator built with Raspberry Pi, RFID reader, LEDs, LCD, and buttons inside a 3D-printed case. The system handles real-time user authentication, bike selection, rental tracking, and balance deduction. It was the first time I built a project that felt like it could become something real, a proof that building this kind of solution is more within reach than most people think. Indeed, just a year later bike-sharing systems appeared in our city!
In the one-day Fabrizio Rocca competition, I led a team to success in a challenge against 10 groups. We developed a Scratch-based game to teach middle school students Mendel’s genetics principles. Additionally, we created an Italian-language tutorial on Wikiversity to guide users in recreating the game.
During my second year of high school (16yo), my classmates and I spent the whole year playing Cookie Clicker on a shared account. Inspired by that, I built my own sports-themed idle game, packed with inside jokes and small memes. I rediscovered it in 2025 and laughed for ten minutes straight. It’s a perfect reminder that I’ve always built things just for the fun of it, but also because I’ve always loved challenging myself and learning by doing.
Together with a software engineer friend, we wanted to build an online tool for book layout and formatting. We knew the problems of the industry: the traditional process is slow, expensive, and handled by designers using complex tools. Our idea was to simplify it: make a tool even authors could use, and with enough depth to serve as a power-tool for designers too. We imagined template libraries, author profiles, and the ability to share layout presets. During market research we discovered two big and established competitors. Both were polished, had solved the hardest technical challenges, and used a one-time payment model: hard to compete with as a small team. Also one was built by someone teaching how to get rich selling kindles, the other was positioned as its rival. We shelved the idea, but got the point: sometimes good will is not enough.
To promote a friend's writing services, we considered launching a podcast. People listen to podcasts for entertainment, but need the illusion of usefulness. So, each episode tackled a deep, complex topic, made engaging through my friend’s experience. For the structure, we took inspiration from the Building a Second Brain Podcast: short, dense episodes, centered on a single topic. We designed a logo, recorded 3 episodes, and gathered feedback. But in the end, we realized that the time required for editing and publishing wasn’t worth the effort. Still, the process taught us a lot about the podcasting world (competitors, optimal episode length, branding challenges, how hard it is to monetize...), and about the real cost of time in a business.
For a few months, I worked on launching an Etsy shop with a graphic designer friend.
The plan was simple: sell printable
products.
We explored several directions but focused on quotes, where we saw clear space for improvement.
But we quickly hit a harsh wall: the Italian business regulations.
Beyond the percentage cut from each sale, just opening a business in Italy means facing a mandatory fixed
tax (IRPEF), around €2000 a year regardless of profit.
For a venture built around 2-3€ products, the math didn’t add up.
It was my first taste of how (Italian...) regulation can crush experimentation, and it validated what many
freelancers in Italy say: the state isn’t on your side.
NB: now I don't consider it a good business, but a good experiment for a 18 years old!
During my final year of high school, a friend and I started a comic strip series about everyday
student life (I wrote, he drew). The humor leaned on Italian school stereotypes:
IPIA (vocational/trade schools) as extraordinarily dumb, Liceo (academic high schools) as
pretentious intellectuals, and ITT (technical institutes, where I studied) as regular
guys desperately trying to get laid.
Despite starting to gain traction, the response from our target audience (high schoolers) was
lukewarm: they gravitated toward nihilistic, melancholic content (BoJack Horseman, Zerocalcare...) rather than
slice-of-life comedy in the style of a reality show (hence the name).
For four years, I played drums in Knurled Chicken Head (name's inspired by knobs), an original band based in Bolzano. It was my first dive into creative collaboration, where I learned to navigate group dynamics and creative disagreements. While we had energy and ideas, we lacked structure: our songwriting suffered from limited music theory knowledge, vocals were our weakest element, and we underestimated marketing focusing only on live shows. The breaking point came when trying to balance midnight rehearsals with 6am university commutes, but the deeper truth was realizing I didn't want to "become a musician when I grew up" ((as with mathematics) hauling gear at 2am after a gig lost its charm fast).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}